
Introduction
Worldwide access to vast amounts of data has changed the business landscape. Competitive marketing depends on knowing how to manage, process, and analyze that data. This article describes the path organizations need to take from collecting data to maximizing its use.
Today’s organizations are undergoing a challenging transformation process around their technical systems. The static software platforms that might have stored and processed a business’ data are no longer sustainable in the current web environment. Enterprises need cutting-edge technology to collect big data in real-time, analyze that data, and then get the information they need to stay competitive in today’s marketplace.
“The data revolution is a movement that focuses on producing, capturing and developing data to improve the way it is used to facilitate change. The data revolution needs a human element to helpshape the future.” MacMillan Dictionary
Machine learning plays a big part in the data revolution. High-end developers design tech systems that train themselves through repetition to perform increasingly more complex analysis and produce increasingly meaningful insights.
DIKW Pyramid
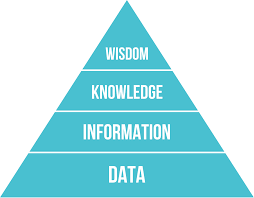
DIKW Pyramid
Also known as the knowledge pyramid, the information hierarchy, and other names, the DIKW (data, information, knowledge, wisdom) pyramid visualizes the steps data takes on the path of transformation to wisdom. A more comprehensive guide can be found in the following article.
Data Transformation
An agile prediction platform transforms data in these primary ways:
- Store, manage, and structure access to data — This function is step 1 Data on the DIKW pyramid. At this stage, data transformations don’t provide information, they only change its form for easier processing.
- Understand data — step 2 Information leads to step 3 Knowledge.
- Make predictions — step 3 Knowledge, when interpreted by a human, leads to step 4 Wisdom.
Data — Store, manage, and structure access to data
Industry-leading software platforms pull in multiple forms of data from multiple sources, process it into a usable form, and store it in a secure cloud warehouse. The human element enters with the decisions that your business needs to make about overall data management. Advice from a professional development team that works agile is critical.
What to keep?
When you design and maintain a system, deciding what data to collect and retain is It’s probably the most influential decision choice your company will ever make.
You might decide in advance based on current information and how you expect to grow, but you’ll probably be wrong. Even the best prediction systems can’t paint an exact picture of your company’s future. Designing this way creates a rigid software platform that’s loaded up with more data than you need and can’t collect and process the data types you might need in the future.
Instead, you need a platform that’s built from the start to scale its data management capabilities along with your business. And you need a team that brings you into the development process as a partner. Then your changing needs and new ideas can be incorporated into your platform every step of the way.
Where?
Consider the massive and ever-increasing amounts and types of data potentially available, your highly sensitive business and customer data, and the growing sophistication of cybercrime. There’s only one choice for secure, reliable, big data storage and management, and that’s the on the cloud.
You might think you need to hire a data infrastructure engineer to customize your data management system, but you don’t. Top industry cloud data management systems like Amazon AWS, Google BigData, and Microsoft MySQL are designed to meet the needs of most businesses. Be pragmatic and weigh the best trade-off between simplicity and customization.
My advice is to choose simplicity.
How?
To decide how to manage your data and who can access and control it, consider these strategies:
- Standardization. Data from all sources is collected and managed in a set format, with predetermined methods and tools. This management design delivers economy, efficiency, speed, and consistency.
- Customization. Data is collected and managed with different methods, tools, and formats, depending on its source and type. This design supports data operations that require complexity and diversity.
- Centralization. All data is stored and managed in one place and processed with the same tools. Centralization works well for large enterprises because it’s a fast, economic, and consistent solution for processing large amounts of data.
- Decentralization. Data is gathered and processed in different ways in different places. Decentralization works for businesses with local branches and other small or personalized businesses that need fast access and responses to local data sources.
- Context dependency. Data is interpreted and processed based on a situation or other factors or influences. Customized and decentralized data management systems often incorporate context dependency.
Who?
The people responsible for standardizing the definition of your data and deciding how to manage it have some big decisions to make.? Will those decision-makers be your leadership team, your tech team, or both? To choose the best strategy, you might create a data council made up of people knowledgeable about different aspects of your business and what technology can best meet your needs. These decisions are critical to the technical health of your business.
The wrong design choices can lead to technical debt and loss of income if your platform doesn’t perform. There’s really no right or wrong answer to whether to create a centralized or decentralized system. It doesn’t have to be one or the other. To meet the needs of their various business sectors and functions, big enterprises often have separate systems designed with different combinations of data operation strategies.
Information and knowledge — understand your data
After you have the right platform, you can begin to understand your data and what it means. This step is third on the DIKW pyramid — Knowledge. Some common ways to gain knowledge from your data are visualization and machine learning techniques like clusterization and prediction systems.
Visualization

Big Data Visualization
With massive amounts and types of new data becoming available all the time, the ability to relevantly visualize data is a skill that organizations must develop if they want to be sustainable and competitive. The field of data visualization is a broad-spanning discipline that encompasses complex analytics and display structures. Dashboards can make a big difference.
To gain knowledge from data, it needs to be easily interpreted and explored. Dashboards with prebuilt queries and visualizations can reduce the friction involved in understanding and viewing your data. The energy and resources you spend on building insightful dashboards are worth it. You can make that process even easier with one of the many user-friendly business intelligence tools that help you create your own shareable visualizations and analytics. Some examples are Chartio, Grafana, and Klipfolio.
Clusterization
The machine learning technique of clusterization is an extremely powerful tool for analyzing data and detecting patterns. Clustering algorithms create sets of similar objects. These algorithms are examples of unsupervised learning, which models the probability densities of given inputs. Because unsupervised learning algorithms aren’t biased, they’re one of the best tools for detecting patterns in datasets.
More information about supervised and unsupervised learning can be found in my following article.
These examples are the types of knowledge you might get from clusterization:
- Are our clients from the east coast or the west coast?
- Do they buy more stylish clothes or casual?
With this knowledge, we have a better understanding of our customers. But knowledge is only helpful if we can apply it to business decisions. At some point, we’ll need actionable insights.
So what are the next steps? How do you move forward from here? Machine learning predictions are one method for transforming our knowledge into deeper insights that we can and translate into actionable plans.
Make predictions
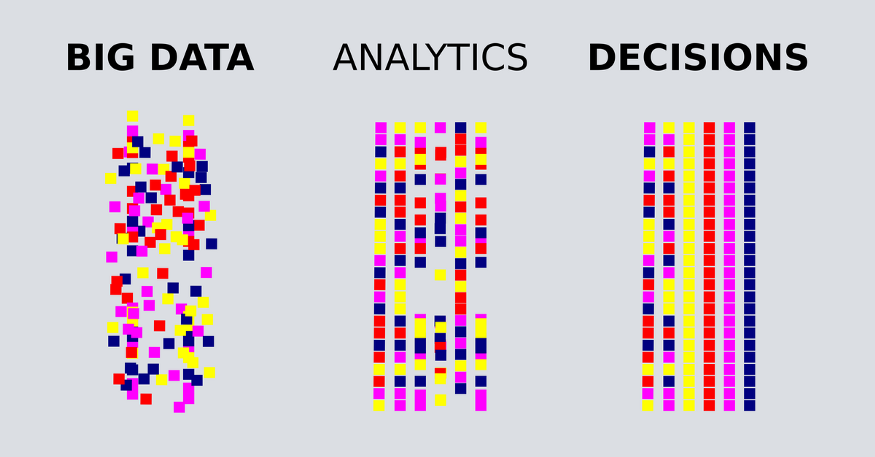
Predictions inform Decisions
Trying to price an article is a classic problem of a prediction system. You’re are really trying to predict users’ behavior:
- Will customers buy your product?
- How much will they be willing to spend on it?
- Will the price combined with potential sales give a return on your investment in production and marketing costs?
Fueled with the knowledge gained from your data, machine learning predictions can give you actionable answers to your pricing questions. An example is an algorithm that predicts
Prediction techniques can be applied to multiple many areas that affect your organization. In supervised learning, we provide our algorithms with a set of correct values to run against and thereby train from. These examples of supervised learning-based predictions can produce actionable knowledge in important areas of business:
- Stock marketing algorithms. With a stock market algorithm, the goal is for the system to learn from the analysis of past market data how to predict future trends.
- Age bracket and the probability of buying a product. In this case, data is analyzed for the buying patterns in different age brackets. Based on past data, the system predicts future purchase probabilities.
- Fraud. Humans review past transactions as fraud or not. The prediction system flags transactions with similar characteristics as potential fraud.
You can test the accuracy of a supervised learning algorithm by running it on past data. Then you can use the new data produced by the test results to improve its the algorithm’s future performance.
Nonstationarity
In our changing world, past data usually isn’t representative of the future. Today’s companies exist in a dynamic environment. Keeping this in mind will help any organization make better decisions based on the past data that they rely on.
When we attempt to make data-based predictions, we first need to identify non-stationary and stationary datasets. These examples show some stationary and nonstationary influences on data:
Stationary. Seasonality is a huge factor in buying activity. Past customer behavior on fixed holidays like Black Friday ad Christmas can predict future behavior.
Nonstationary. Economic ups and downs are nonstationary changes that usually can’t be accurately predicted.
Interpretability
Organizations need to be able to interpret the data produced by their algorithms. A platform might have a lot of information about past behavior. But to create a prediction, we need to understand which datasets are relevant to the questions we ask. Which factors are important? And how important is each factor?
When you study your business metrics, you might see correlations based on past data. But correlations don’t necessarily indicate a cause-effect relationship. As an example, you might find that most of your buyers are women. Your interpretation of that finding might be that your website is more attractive to women than men. But this kind of assumption can be a dangerous way to make marketing decisions. Whenever you interpret data in a superficial or biased manner, it might show a correlation that isn’t actually the root of the problem.
Our brains have a strong tendency to confuse correlation with cause-effect relationships. This website has some examples of “spurious correlations” and I also wrote an article about “causation vs correlation”. This type of cognitive bias is a huge deal that affects everything from minor decision making to medical research. In fact, such faulty thinking has dictated health recommendations for decades.
Wisdom — from prediction to decision
After we get machine learning predictions, we move to the top of the DIKW pyramid. Decisions about how to apply those predictions require wisdom and must be made by a human. A company’s values, mission, and business acumen must all guide what actions and investments to make based on human analysis of predictions. Right or wrong decisions impact not only an enterprise’s chance of success but also external factors like its customers, social issues, and the environment.
References
Stanford University (2019). “Turn Data into Insights with Predictive Modeling” Course.
Wallace, Danny P. (2007). “Knowledge Management: Historical and Cross-Disciplinary Themes.” Libraries Unlimited. pp. 1–14. ISBN 978–1–59158–502–2.
Anthony Figueroa (2019). “Correlation is not Causation”. https://towardsdatascience.com/correlation-is-not-causation-ae05d03c1f53
Anthony Figueroa (2019). “DIKW Pyramid”. https://towardsdatascience.com/rootstrap-dikw-model-32cef9ae6dfb
Anthony Figueroa (2019). “Data Demystified — Machine Learning”https://towardsdatascience.com/data-demystified-machine-learning-3b40ec435ff2


